
HowTo: Ubuntu OpenVPN Server Installation
Understanding the Importance of VPNs === In today’s digital age, where privacy and security are paramount concerns, virtual private networks (VPNs) have become an essential tool for individuals and businesses alike. A VPN creates a secure and encrypted connection between your device and the internet, allowing you to browse the web anonymously and protect your
27 Dec

Bare Metal Servers vs Cloud Services: A Comparison
When it comes to hosting applications and services, there are several options to choose from, including bare metal servers and cloud services. In this article, we’ll compare these two options in order to help you decide which one is right for your needs. What are Bare Metal Servers? Bare metal servers, also known as dedicated
27 Dec

HowTo: Install Pritunl VPN Server on Centos 8
Pritunl is a free and open-source VPN server that allows you to securely connect to your network from remote locations. In this tutorial, we’ll show you how to install and configure Pritunl on CentOS 8. Before starting, make sure that you have a fresh installation of CentOS 8, with the latest updates and patches applied.
27 Dec
HowTo: Install Plesk on CentOS 8
Plesk is a web hosting control panel that allows you to manage your web hosting environment, including websites, domains, email accounts, and more. In this tutorial, we’ll show you how to install Plesk on CentOS 8. Before starting, make sure that you have a fresh installation of CentOS 8, with the latest updates and patches
20 Apr

Streaming vs. Coronavirus: Industry Update During the Pandemic
The Global pandemic of 2020 caused by the outburst of COVID-19 coronavirus has affected the lives of millions of people and their businesses. Most industries have experienced a significant impact due to quarantines initiated in countries all across the World. International travel, restaurant business, apparel, automotive, luxury products all have taken a great hit from
13 Apr

Microsoft Windows Server 2016 & 2019 Instances
Latest Microsoft Windows Server 2016 and 2019 instances are now available for immediate ordering. Get a fully licensed Microsoft Windows server at a fraction of the cost of other cloud server providers. It is possible to order both Evaluation and Licensed instances. The difference is that Evaluation license expires after 6 months and the server
23 Mar
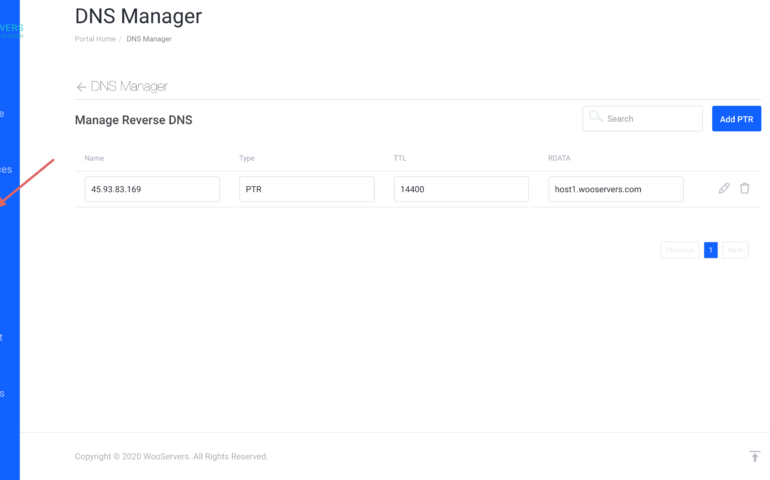
rDNS Settings
We are happy to announce general public availability of the “RDNS Management” feature inside our control panel at http://helpdesk.wooservers.com/ From now on, if you have eligible service (Latest SSD Cloud Instances), you will be able to easily configure RDNS for your server, without the need to open ticket with our support departments. Please check out
25 Feb

Special Deal for Flussonic Instances
Flussonic is one of the top video streaming platforms on the market, allowing you to build Live Streaming, VOD and Re-streaming applications and services. WooServers has been working on partnering with Flussonic in order to provide the best quality service and support with pre-installed Flussonic Instances which would allow you to setup Flussonic quickly on
01 Jan

Top 10 Plesk Security Guidelines
Plesk is undoubtedly one of the leading web hosting control panels on the market in 2020. It offers a great range of features, while also featuring a great UI. However, like any control panel it is paramount to manage Plesk Security to minimize the risk of being hacked. Here we present the list of Highly
26 Dec

WooServers News: December 2019
We are happy to provide an update on what’s happening inside of WooServers. At WooServers we strive to provide great services at best prices. As many of you know, in the past years we have been focusing on Dedicated Servers and Virtual Machines as the basis of our offers. However, due to general changes in
Recent Posts




Recent Comments